
Building a RAG App on Strava Data
...or how I bit the AI bullet


Ears to the ground…
Intrigued by the current AI trends across the industry, I was eager to try it out for something practical—to get a grasp on the concepts, terminologies, and see if I could leverage open source tools. The icing on the cake, I thought, would be improving on something I'd previously built.
..a simple RAG application
Let me talk about a very simple RAG1 application that I ended-up building. Few years ago, I had played-around with Strava2 APIs to fetch my activity data (from prehistoric era — when I was active) — the whole experience was fun as I’d experimented with a simple service (using (the now defunct) snips.ai , Raspberry Pi, and an Xmini). The application would:
accept voice input like “how much did I run (/bike) last week (/month/year)”
summarise my run and biking activities’ totals for a given duration, and then,
respond to be via audio.
(Here’s a demo video from back then)
In this new Strava-RAG project, the aim was to cash-in on that past experience with Strava APIs, and see how it can be made better. I got a simple project outline, and capabilities generated using ChatGPT.
Admittedly, since I have a soft corner for PostgreSQL, I was also keen on utilising its vector database3 extension.
The overall system goal was simple, and can be worded as:
A system that can answer question in plain English about my (or any athlete’s) activities like “What year was I the most active in”, or something more complex like “Show me the activities where I performed like my best activity in 2019”, and so on…
The following high-level functionalities were required:
Fetch: Authenticate and fetch activities from Strava
Persist: Store activities in the PostgreSQL
Query: Enable natural language querying on the stored activities using LLM
Let’s dive in!
Fetch: Authenticate, Authorize, and Fetch data from Strava
Strava uses OAuth protocol for authentication, which turned out to be a bit more involved4 than what it sounds in theory, so let me lay it down simply.
Here’s the general flow:
You register your app with Strava and get a Client ID and Client Secret.
You direct the user (yourself, in this case) to a special authorization URL that includes your Client ID, requested permissions (scopes), and a redirect URI.
On approval, Strava redirects back to your specified URI with an authorization code.
You exchange this code (along with your Client Secret) for an access token and refresh token.
You use the access token to fetch actual activity data. When it expires (typically after 6 hours), you use the refresh tokento get a new access token without re-authorization.
This boiled down to two basic functions:
# Get the token
get_token(auth_code) -> access_token
# Use token to get activities
get_activities(access_token) -> activities[]Note that the tokens expire - so this also involves an additional quirk of adding a refresh_token logic to the backend code.
The output of get_activities is an array of activities, which are then dumped to a JSON file.
Persist: Store activities in the PostgreSQL
Once the list of activities have been successfully fetched, the next step is to push them to the database. While doing that we also convert relevant information to embeddings to enable intelligent querying.
Following was the format of (would-be) embedded sentences.
{activity['name']} {activity['type']} {activity['distance']} meters in {activity['elapsed_time']} seconds"
All the activities were converted to the above format, and then I utilised the Python-provided sentence-transformer model to do the string → embedding transformation. For example, a sentence that is formed by replacing the placeholders in the above sentence would be:
morning cycling ride 10034 meters in 1934 seconds
which would then get converted via sentence-transformer model to a 384-dimension vector like so:
[0.034342 0.0534622 .0324592 0.0441267 …]
each of which gets stored for each activity record.

It’s easy to write a simple iteration to do the same for the entire set of activities, and store it into a DB table. This table would then become our source of truth, and would be kept updated with new activities over time.
With this, I was done with the heart of the application. What remained was to enable querying in natural language, which could then leverage these embeddings.
Query: Enable natural language querying on the stored activities using LLM
I must admit that initially I took this step for granted, naïvely assuming that the LLM will take care of everything. It wasn’t to be.
The platform of choice was Ollama, since I wanted something lightweight, and local. Based on ChatGPT’s recommendation, I went ahead to install Mistral on Ollama. As per the default configuration, the LLM was available via a (local) API call, for basic querying.
Control Flow
The overall control flow can be envisioned as:
Accept user’s query
Process the query in the backend and return the query results
Encode the query using the
sentence-transformerUse the resultant embedding in the similarity-based query on the database
Return the query results
These query results then become the additional (/augmented) context that has to be passed to the (Mistral) LLM
Pass the additional context, and the base prompt to Mistral. This prompt was of the form:
You are an assistant which summarizes Strava activity data, based on the retrieved activity information below. Retrieved Activity Context: {additional_context} Instructions: ... ...
The high-level flow can be illustrated like so:
┌─────────────────┐
│ USER │
│ Asks Question │
│"Best 2023 runs?"│
└─────────┬───────┘
│
▼
┌─────────────────┐
│ WEB FRONTEND │
│ (HTML/CSS/JS) │
└─────────┬───────┘
│ HTTP POST
▼
┌─────────────────┐
│ FLASK API │
│ (Python) │
│ /query endpoint │
└─────────┬───────┘
│
▼
┌─────────────────────────────────────┐
│ RAG ENGINE │
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ RETRIEVE │ │ GENERATE │ │
│ │ │ │ │ │
│ │ Find best │ │ Ollama | |
│ │ | | + Mistral | |
│ │ matching │─▶│ (LLM) │ │
│ │ activities │ │ │ │
│ └─────────────┘ └─────────────┘ │
└─────────┬───────────────────────────┘
│
▼
┌─────────────────┐
│ POSTGRESQL │
│ DATABASE │
│ │
│ • Activity data │
│ • Vector search │
│ • Smart filters │
└─────────┬───────┘
│
▼
┌─────────────────┐
│ RESPONSE │
│ │
│ "Here are your │
│ best runs: │
│ 🏃 Oct 1, 2023 │
│ 🏃 Sep 28, 2023"│
└─────────┬───────┘
│
▼
┌─────────────────┐
│ USER │
│ Sees Results │
└─────────────────┘Prompt Refinement
Was this enough? Nope — the prompt did need refining to handle cases where an any infrequent activity was queried, for example ‘Weight Training’, etc.
Another refinement needed for the interpretation of ‘Best’. That is, while the ‘Best’ for a given Run/Ride activity would be determined based on Speed, Duration, etc. — the same cannot be said for other types of activities. In the case of ‘Hiking’ or ‘Weight Training’, for example, parameters to determine “Best” are quite different — e.g. ‘Elevation’ in the case of Hiking. Similarly, there were other edge cases that required instruction (prompt) refinement, and logic-based handling!
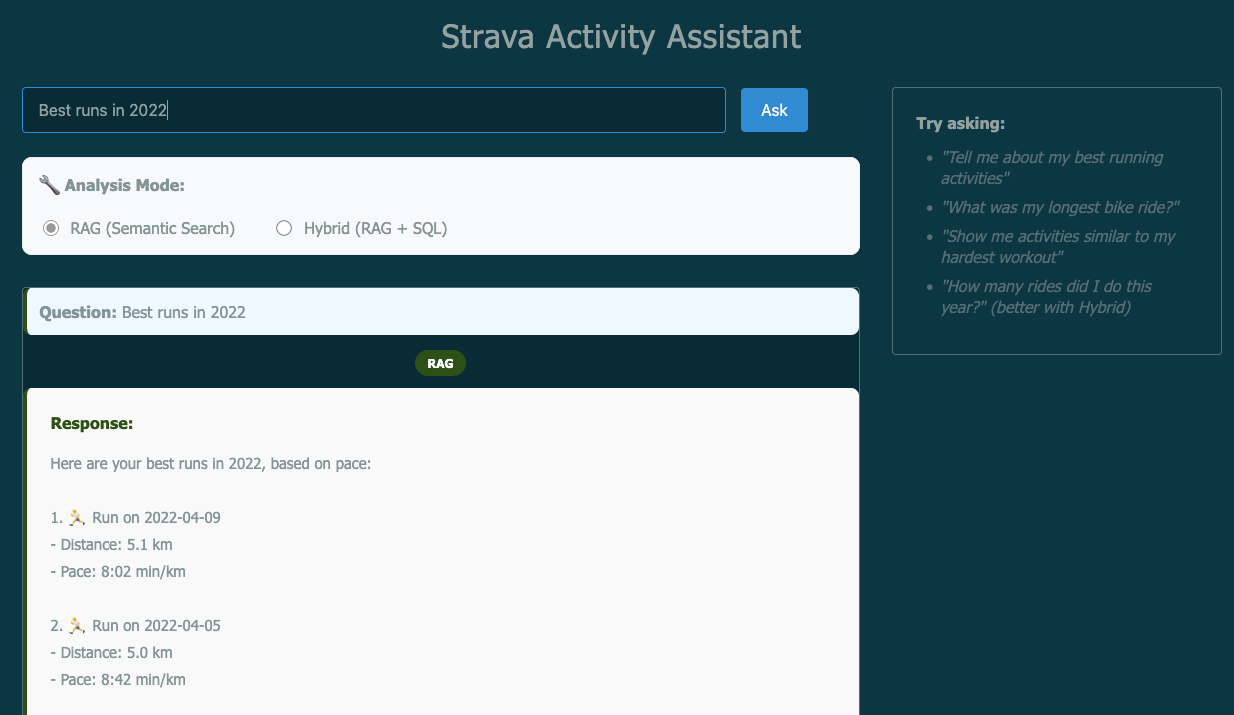
A Basic UI
Then I went ahead to add a simple, browser-based UI to the application, because until then it was all CLI-driven. This was trivial using Claude which created a basic (HTML/JS) UI, which could be seamlessly integrated to the existing Flask app.
Next steps..
In subsequent posts, I want to build-up on this basic project and to mimic a production system as I think that’s a topic which requires adequate attention. In other words I want to focus on: how does this all come together, and, more importantly, sustain over time, as would in a real-world system!
You can find the above project here.
Retrieval Augmented Generation (RAG): A system that enhances (augments) a language model’s responses by retrieving relevant information from an external source — database, documents, etc.
Strava is a very popular activity-tracking app. It’s also a social network of sorts for the users, in that users can subscribe to each other’s “activity feed”, and react on it
Vector database: A kind of database that stores text as numbers (called embeddings), making it possible to run mathematical operations — like measuring how similar two pieces of text are, by comparing their number arrays.