
A Spark learning.

About a month back, I'd done something I was not very proud of -- a piece of code that I was not very happy about -- and I had decided to get back to it when time permits. The scenario was something close to the typical Word Count problem, in which the task required counting words at specific indices, and then print the unified count per word. Of course, there were many other things to consider in the final solution since a streaming context was being dealt with -- but those are outside the purview of what I'm trying to highlight here. An abridged problem statement could be put as:
Given a comma-separated stream of lines, pick the words at indices
jandkfrom each line, and print the cumulative count of all the words atjth andkth positions.
So the 'crude' solution to isolate all the words was:
Implement a
PairFunction<String, String, Integer>, to get all the words at a given indexUse the above function to get all occurrences of words at index
j, and get a Pair (Word -> Count) RDDUse the same function to get all occurrences of words at index
k, and get another Pair (Word -> Count) RDDUse the RDD
union()operator to combine the above two RDDs, and get a unified RDDDo other operations (
reduceByKey, etc. ...)
As is apparent, anyone would cringe at this approach, especially due to the two passes (#2, #3) over the entire data set -- even though it gets the work done! So I decided to revisit this piece, with the tool of additional knowledge about what all Spark offers. One useful tool is the flatMap operation that Spark Java 8 offers. By Spark's definition:
flatMap is a DStream operation that creates a new DStream by generating multiple new records from each record in the source DStream
Given our requirement, this was exactly what was needed -- create two records (one for each jth and kth index word), for each incoming line. This would, of course, benefit us in that we have the final (unified) RDD in just a single pass of the incoming stream of lines. I went ahead with a flatMapToPair implementation, like so:
JavaPairDStream<String, Integer> unified = lines.flatMapToPair((s) -> {
String a[] = s.split(",");
List<Tuple2<String, Integer>> apFreq = new ArrayList<>();
apFreq.add(new Tuple2<>(a[Constants.J_INDEX],1));
apFreq.add(new Tuple2<>(a[Constants.K_INDEX],1));
return apFreq.iterator();
}); To further validate the benefits, I ran some tests* with datasets ranging from 1M to 100M records and the benefits of flatMap approach were more and more pronounced as data grew bigger. Following were the observations.
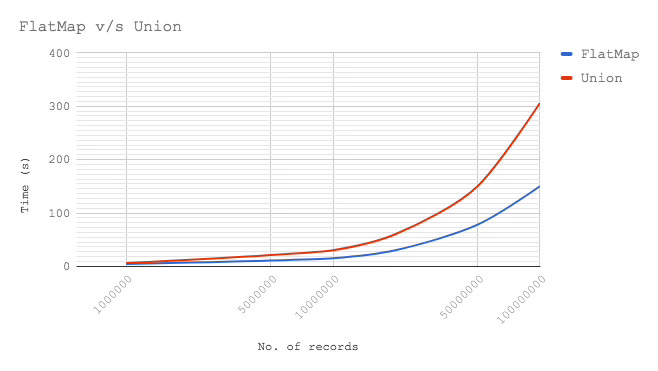
As we can see, whilst the difference is ~2s for 1 million records, it becomes almost twice as we reach 10M and more than twice at around 100M mark. It's therefore, obvious that production systems (e.g. a real-time analytics solution), where data the volume is much higher, need to be cautious about the choice of each operation (transformation, filtering or any other action), as these govern the inter-stage as well as the overall throughput of a Spark application.
* Test conditions: - Performed on a 3-Node (m4.large) Spark cluster on AWS, using Spark 2.2.0 on Hadoop 2.7 - Considers only the time spent on a particular stage (union or flatMap), available via Spark UI - Each reading is an average of time taken in 3 separate runs